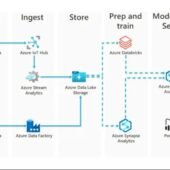
Introduction:
Azure Data Factory (ADF) empowers organizations to create, schedule, and manage data workflows in the cloud. Transformations play a pivotal role in shaping raw data into actionable insights. However, ensuring optimal performance during data transformations is critical for timely and accurate decision-making. In this blog, we’ll explore top strategies to optimize transformation performance in Azure Data Factory.
1. Select the Right Transformation Approach:
Azure Data Factory offers two transformation approaches: Data Flow and Mapping Data Flow. Choose the one that aligns with your data transformation complexity. Data Flow is ideal for ETL operations, while Mapping Data Flow is suitable for complex transformations involving big data clusters.
2. Efficient Data Partitioning:
Partitioning data enables parallel processing, significantly boosting performance. When working with large datasets, split data into smaller partitions to take full advantage of ADF’s scalability and process data concurrently.
3. Consider Pushdown Processing:
Leverage the power of Azure Integration Runtimes and pushdown processing to perform transformations closer to the data source.
4. Proficient Data Types and Formats:
Opt for data types and formats that optimize data storage and processing. Use columnar storage formats like Parquet or ORC, as they reduce data size and boost query performance during transformations.
5. Filter Early, Filter Often:
Apply filters as early as possible in your data transformation process. Reducing the data volume before processing minimizes the workload, leading to faster transformations.
6. Aggregation and Grouping:
Utilize aggregation and grouping functions effectively. Minimize the number of aggregations and groupings for better performance.
7. Optimize Joins:
Join operations can be resource-intensive. Choose the appropriate join type (inner, outer, left, right) and consider using broadcast joins for smaller datasets. Implement filters before joining to reduce the amount of data processed.
8. Data Skew Handling:
Data skew, where some values have significantly more occurrences than others, can slow down transformations. Use techniques like salting or hashing to evenly distribute data, preventing performance bottlenecks.
9. Runtime Settings and Cluster Size:
Adjust the runtime settings and cluster size based on your transformation needs. For Mapping Data Flows, consider using big data clusters for resource-intensive tasks.
Conclusion:
Efficient transformations are the backbone of effective data processing in Azure Data Factory. By implementing these performance optimization strategies, organizations can ensure faster data transformations, reduced resource utilization, and improved overall efficiency.
#adf #azuredatafactory #adfperformanceoptimization #azuredataengineer #azuredataarchitecture #azuredatalake